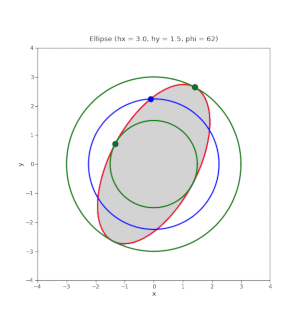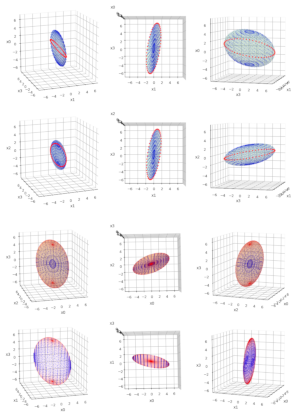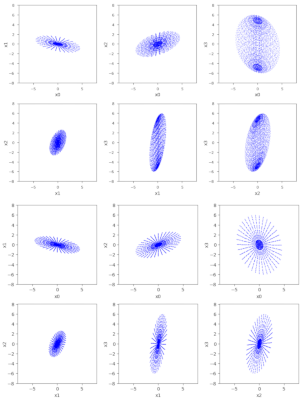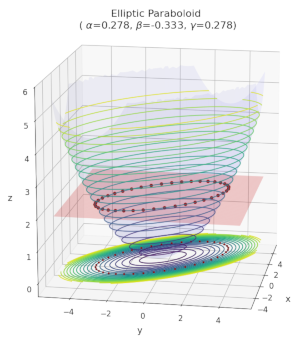
Quadratic form functions as graph functions – I – level sets and gradients
The last months I have seldom written posts in this blog. The reason is that I am occupied with a book about “The geometry of Multivariate Normal Distributions”. Which will cover a lot more topics than the ones discussed in this blog so far. One of those topics is the use of quadratic form functions as graph functions to produce… Read More »Quadratic form functions as graph functions – I – level sets and gradients