AdamW for a ResNet56v2 – VI – Super-Convergence after improving the ResNetV2
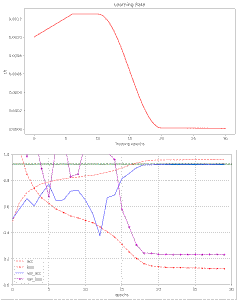
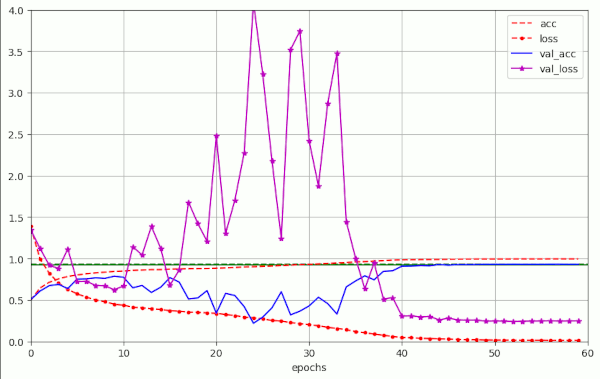
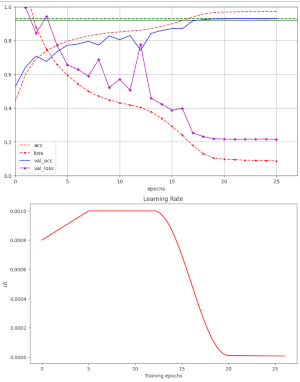
In previous posts of this series I have shown that a Resnet56V2 with AdamW can converge to acceptable values of the validation accuracy for the CIFAR10 dataset – within less than 26 epochs. An optimal schedule of the learning rate [LR] and optimal values for the weight decay parameter [WD] were required. My network – a variation of the ResNetV2-structure… Read More »AdamW for a ResNet56v2 – VI – Super-Convergence after improving the ResNetV2