We can use PyQt to organize output of Machine Learning applications in Qt-windows outside of Jupyterlab notebooks on a Linux desktop. PyQt also provides us with an option to put long running Python code as ML training and evaluation runs into the background of Jupyterlab and redirect graphical and text output to elements of Qt windows. Moving long lasting Python jobs and ML algorithms to the background of Jupyterlab would have the advantages
- that we could run short code segments in other notebook cells in the meantime
- and keep up the responsiveness of PyQt and Qt-based Matplotlib windows on the desktop.
In the first two posts of this series
- Using PyQt with QtAgg in Jupyterlab – I – a first simple example
- Using PyQt with QtAgg in Jupyterlab – II – excursion on threads, signals and events
we saw that PyQt and its GUI-widgets work perfectly together with Matplotlib’s backend QtAgg. Matplotlib figures are actually handled as special Qt widgets by QtAgg. We also gathered some information on threads in relation to Python and (Py)Qt. We understood that all (Py)Qt-GUI-classes and widgets must be run in the main thread of Jupyterlab and that neither Qt-widgets nor Matplotlib functions are thread-safe.
As a consequence we need some thread-safe, serializing communication method between background threads and the main thread. Qt-signals are well suited for this purpose as they end up in the event queue of target threads with fitting slots and respective functions. The event queue and the related event loop in the main thread of a Qt application enforce the required serialization for our widgets and Matplotlib figures.
In this post I want to discuss a simple pattern of how to put workload for data production and refinement into the background and how to trigger the updates of graphical PyQt windows from there. The pattern is based on elements discussed in the 2nd post of this series.
Pattern for the interaction of background threads with Qt objects and widgets in the foreground
You may have read about various thread-related patterns as the producer/consumer pattern or the sender/receiver pattern.
It might appear that the main thread of a Jupyter notebook with an integrated main Qt event loop would be a natural direct consumer or receiver of data produced in the background for graphical updates. One could therefore be tempted to think of a private queue as an instrument of serialization which is read out periodically from an object in the main thread.
However, what we cannot do is to run a loop with a time.sleep(interval)-function in a notebook cell in the main thread for periodic queue handling. The reason is that we do not want to block other code cells or the main event loop in our Python notebook. While it is true that time.sleep() suspends a thread, so another thread can run (under the control of the GIL), the problem remains that within the original thread other code execution is blocked. (Actually, we could circumvent this problem by utilizing asyncio in a Jupyterlab notebook. But this is yet another pattern for parallelization. We will look at it in another post series.)
Now we have two options:
- We may instead use the particular queue which is already handled asynchronously in Jupyterlab – namely the event queue started by QtAgg. We know already that signals from secondary (QThread-based) threads are transformed into Qt-events. We can send relevant data together with such signals (events) from the background. They are placed in the main Qt event queue and dispatched by the main event loop to callbacks.
- If we instead like to use a private queue for data exchange between a background and the main thread we would still use signals and respective slot functions in the main thread. We access our queue via a slot’s callback and read-out only one or a few new entries from there and work with them.
I will use the second option for the exchange of larger data objects in another post in this series. The pattern discussed in this post will be build upon the first option. We will nevertheless employ our own queue for data exchange – but this time between two threads in the background.
Short running callbacks in the main thread
According to what we learned in the last post, we must take care of the following:
The code of a callback (as well as of event handlers) in the main thread should be very limited in time and execute as fast as possible to create GUI updates.
Otherwise we would block the execution of main event loop by our callback! And that would render other graphical objects on the desktop or in the notebook unresponsive. In addition it would also block running code in other cells.
This is really an important point: The integration of Qt with Jupyterlab via a hook for handling the the Qt main event loop seemingly in parallel to IPython kernel’s prompt loop is an important feature which guarantees responsiveness and which we do not want to spoil by our background-foreground-interaction.
This means that we should follow some rules to keep up responsiveness of Jupyterlab and QT-windows in the foreground, i.e. in the main thread of Jupyterlab:
- All data which we want to display graphically in QT windows should already have been optimally prepared for plotting before the slot function uses them for QT widget or Matplotlib figure updates.
- Slot functions (event handlers) should use the function Qwidget.Qapplication.process_events()
to intermittently spin the event-loop for the update of widgets. - The updates of PyQt widgets should only periodically be triggered via signals from the background. The signals can carry the prepared data with them. (If we nevertheless use a private queue then the callback in the main thread should only perform one queue-access via get() per received signal.)
- The period by which signals are emitted should be relatively big compared to the event-loop timing and the typical processing of other events.
- We should separate raw data production in the background from periodic signal creation and the related data transfer.
- Data production in the background should be organized along relatively small batches if huge amounts of data are to be processed.
- We should try to circumvent parallelization limitations due to the GIL whenever possible by using C/C++-based modules.
In the end it is all about getting data and timing right. Fortunately, the amount of data which we produce during ML training runs, and which we want to display on some foreground window, is relatively small (per training epoch).
A simple pattern for background jobs and intermediate PyQt application updates
An object or function in a “worker thread” calculates and provides raw data with a certain production rate. These data are put in a queue. An object or function in a “receiver thread” periodically reads out the next entries in the queue. The receiver knows what to do with these data for plotting and presentation. It handles them, modifies them if necessary and creates signals (including some update data for PyQt widgets). It forwards these signals to a (graphical) application in the main foreground thread. There they end up as events in the Qt event queue. Qt handles respective (signal-) events by so called “slots“, i.e. by callbacks for the original signals. The PyQt- application there has a graphical Qt-window that visualizes (some of) the data.
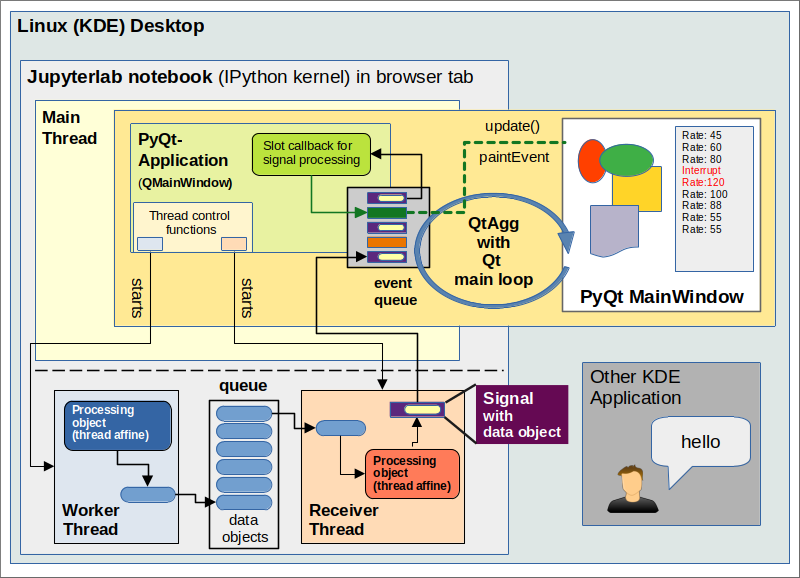
So, we utilize two background threads in this approach. Some more details for the scenario displayed in the drawing above:
Main thread: Among other applications on our desktop we have a Jupyterlab Python notebook in a browser tab. The running interpreter with the IPython kernel defines our main thread. QtAgg provides the integration with Qt: It starts a QApplication with a Qt main event loop. This loop evaluates events for potential Qt application windows and dispatches the events for a handling by callbacks in the main thread.
The code of a notebook cell starts an PyQt application (a QMainWindow-object) which opens an interactive Qt-window on the desktop. The PyQt-application also starts the main and the receiver threads and objects with a respective affinity in the background.
Worker thread: The production of raw data for later updates of widgets and plots in the foreground can very often be done by modules which are C/C++-based (Numpy-array-functions, linear algebra libraries) or by code which does not affect the CPU at all (ML training with Tensorflow on the GPU!). The hope is that Python GIL-blocking for a parallel execution of threads does not occur too often. Meaning that the OS can run the main thread and the worker thread most of the time really in parallel on different CPU cores.
Receiver Thread: The receiver thread picks single blocks or batches of raw data and brings them into an optimal form for further handling by PyQt widgets or Matplotlib functions. I call this “data refinement”. Also here we may hope that GIL-blocking of thread parallelization can be avoided to a large degree. Often Numpy array-operations can be applied in this thread, too.
The receiver thread sends signals (with few prepared data, like e.g. messages) to the application in the main foreground thread. The signals create events in the event queue handled by the main loop.
Main thread: The events of the event queue are dispatched to the slot callbacks which in turn issue update()-commands and thus trigger paintEvents for PyQt-widgets. This includes widgets for Matplotlib figures. Elements of the Qt-window are eventually redrawn.
All in all we thus have a chance to establish a well balanced load distribution between different threads. Furthermore there is a real chance to circumvent the GIL for many operations by cleverly using Numpy and ML Tensorflow libraries.
As all threads share the same memory space we can put a lot of data into Numpy arrays and operate on them. For example in the receiver thread. This reduces the amount of data to be transferred via signals to the main thread.
Why is the drawing correct regarding signals?
The drawing above would in principle have to be justified as events and signals basically are two different things in Qt. However, in the 2nd post of this series we have already learned that signals between different threads are turned into events ending up in the event queue of the target threads. This requires that we use the default for inter-thread communication namely an asynchronous “queued connection” for sending and receiving signals. In this case the signal moves through the event queue of our receiver thread – which in our case is the main thread. The main thread is the only thread where GUI-related events and thus also updates (paintEvents)!) of GUI widgets can be handled.
Would signals of a widget or object in the main thread not interfere with serialized signals from background threads?
Now you may have read that standard signals emitted by widgets after status changes lead to a direct, i.e. synchronous execution of connected callbacks in the main thread. Doesn’t this lead to chaos and threaten thread-safety? In my opinion at least not directly.
One should not forget the following: Commands in one and the same thread are executed in a clear timely order (even if you use asyncio). Further processing of other signals and also the event loop stops until the slot’s callback function returns. And the creation of paintEvents by update requests again serialize the changes of the GUI-widgets on the screen because they are also handled asynchronously through the event queue and the main event loop. One signal and/or event is completely handled within the main thread before the next one is processed. During processing we can care about a safe status of all affected variables. In case of doubt you can still protect some affected global variables by the QMutex mechanism of Qt. But this should seldomly be required.
The status information related to all secondary effects of update-requests() which may lead to further events (like when a scrollbar has to be painted and to be adjusted) end up at the widgets in the main thread. No required information can get lost, as it could and would be the case if a widget function had directly been invoked from a background thread.
Conclusion
In this post I have presented a first pattern of how to deal with data production and data refinement in the background of Jupyterlab’s main thread running Qt’s main event loop. Two background threads work together to produce optimal batches of data for alter updates of Qt-widgets and Matplotlib figures in the foreground. One background job sends respective signals to the main thread and create events in the main event loop. Slots and their callback functions in the foreground handle the events asynchronously and request widget updates based on the received data and information.
In the next post I will discuss a simple example which follows our pattern.