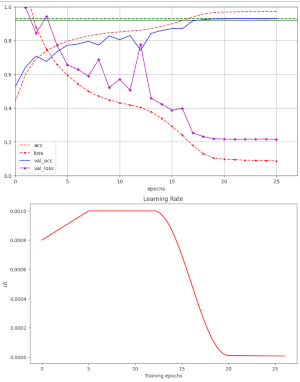
Performance of PyTorch vs. Keras 3 with tensorflow/torch backends for a small NN-model on a Nvidia 4060 TI – I – Torch vs. Keras3/TF2 and relevant parameters
Today’s world of Machine Learning is characterized by competing frameworks. I am used to the combination of Keras with the Tensorflow2 [TF2] backend, but have turned now to using PyTorch in addition. As a beginner with PyTorch, I wanted to get an impression about potential performance advantages in comparison with the Keras/TF2 framework combination. I had read about significant performance… Read More »Performance of PyTorch vs. Keras 3 with tensorflow/torch backends for a small NN-model on a Nvidia 4060 TI – I – Torch vs. Keras3/TF2 and relevant parameters