One of the problems I recently ran into was the coexistence of Tensorflow2 [TF2] and PyTorch in the very same virtual Python environment. I just wanted to make experiments to compare the performance of some Keras-based models with the TF2-backend on one side and, on the other side, with the PyTorch-backend. My trouble resulted from a mismatch of two CUDA/cudnn installations. One was my own system-wide installation. The other one was automatically performed by the pip-installer to fulfill dependencies of the “torch”-packet. The mismatch led to program execution errors regarding cudnn. In this post I suggest a quick but somewhat dirty remedy for users that have the same problem.
Addendum, 3/28/2025: After a day of confusing trials, I came to the conclusion that the recipe below only works for clearly separated PyTorch and Keras/TF2-models in your scripts or Jupyterlab notebook,. I.e., the setup and training of your model must either completely be done with plain PyTorch methods – or completely with TF2/Keras methods. However, a global CUDA installation may still interfere with a local one induced by the torch packet in other cases. This may e.g. happen, when you use Keras 3 with a PyTorch backend – and mix PyTorch dataloaders and PyTorch training loop with a Keras-based neural network model. In such experiments, your Linux shell environment variables must not indicate any paths to your global CUDA installation. I will soon write a post about this topic.
The problem
Regarding Python, I always work with virtual Python environments – depending on available Python versions for my Linux-system and to maintain a separation of certain rather specific ML-projects. My present problems had their origin in the fact that PyTorch comes as a module (“torch”) which, when it gets installed via “pip“, also invokes a resolution of dependencies to specific CUDA and cudnn runtime modules. These extra SW-packets are then automatically installed in your virtual Python environment. My experience is that an environment variable CUDA_HOME pointing to an already existing global CUDA-installation is ignored during this process.
On the other side I have always had a policy to install CUDA/cudnn system-wide on my Linux PCs. This habit stems from a time when I worked with Tensorflow, only, for my ML/AI-experiments. Now, with Pytorch as a very useful parallel framework for experiments with LLMs and Hugging Face, this habit comes with some disadvantages. With a parallel installation of TF and PyTorch, I not only have to spend double storage space for two CUDA installations. In addition there is no guarantee that the CUDA/cudnn versions match. Unfortunately, a mismatch will lead to errors on the TF2-side.
PyTorch just takes the local CUDA/cudnn installation it itself came with. And, of course, works flawlessly with it. The problem starts when you want TF2-based statements to run, too, in the very same Python code or in separate Python code executed in the same virtual Python environment. An example of the resulting error message for some neural network program is given below:
E0000 00:00:1741086203.749202 26253 cuda_dnn.cc:522] Loaded runtime CuDNN library: 9.1.0 but source was compiled with: 9.3.0. CuDNN library needs to have matching major version and equal or higher minor version. If using a binary install, upgrade your CuDNN library. If building from sources, make sure the library loaded at runtime is compatible with the version specified during compile configuration.
Interestingly, this error only came up when I started to train a Keras-based CNN-model, i.e. after having set up and compiled the model, with TF2 statements.
Normally, I direct TF2 to pick the global CUDA installation via providing respective environment variables for the shell that starts my Jupyterlab – and settings in “/etc/alternatives” (on my Leap systems).
A startup script for Jupyterlab might e.g. contain the following respective statements for a CUDA 12.8 installation:
export PATH=/usr/local/cuda-12.8/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}In my case the global CUDA installation has version 12.8 and cudnn has version 9.7.1. Without any local, Pytorch-induced CUDA-installation in the virtual Python environment, TF2 does the right thing and works perfectly under the hood of the Jupyterlab IDE. But, after a Pytorch installation, TF2 unfortunately picks the wrong version of cudnn – namely the one installed locally by PyTorch. The result is a mismatch with respect to the cudnn-version used during the TF-build. This mismatch is detected by TF2 and leads in my case to the error displayed above. [Do not ask me why the error message refers to a version 9.3. I have not yet analyzed which of the installed configuration scripts leads to this behavior.]
Unclear information from the Pytorch and TF2
The analysis of a mismatch situation is not made easier by messages you may get from PyTorch or TF2 in a Python program. For exampel, in my situation I get the following response from PyTorch
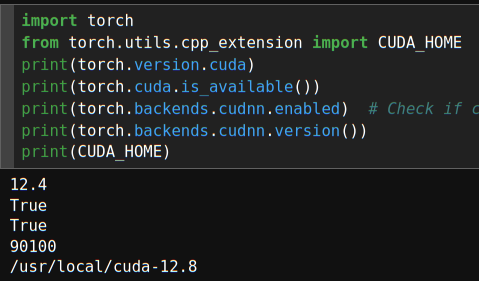
The first 4 messages describe that CUDA 12.4 and cudnn 9.1.0 of a respective local installation in the virtual Python environment. It is indicated that these versions are successfully used.
TF2 also gives us some hints – which, however, must be interpreted differently :
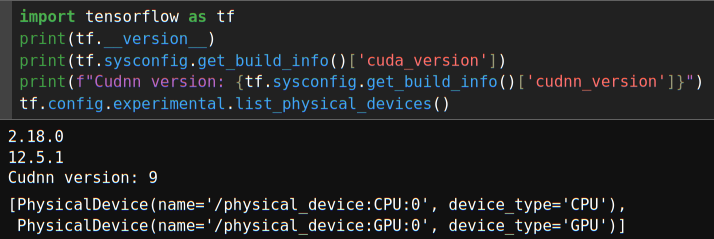
The 2nd and the 3rd line only give us an information about which (minimum) versions of CUDA and cudnn TF2 expects, because it was built against these versions – but not what it actually finds and uses on the system. As said, my actual system-wide CUDA installation is of version 12.8 and cudnn of version 9.7.1. And my present version of the tensorflow 2.18 module works well together with these latest version of CUDA/cudnn – despite the above messages.
On the Linux shell relevant information about the CUDA environment looks differently:
mytux:~ # nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:20:09_PST_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0Ways out of the problem
In my opinion there are 4 ways out of the problem – if you do not want to change the installed TF scripts or to perform your own compilation of PyTorch:
- Use two different virtual environments for PyTorch and for TF2 experiments.
- Fumble around with TF2-version and torch-versions in one and the same virtual Python environment, such that both frameworks are compatible with the CUDA-installation enforced by PyTorch. Or by tensorflow, for which a fitting CUDA version be added via a modification of the pip command ( pip install tensorflow[and-cuda] ). ]
- Adapt the version of your global CUDA installation to one corresponding to the PyTorch enforced one.
- Use the function tensorflow.load_library () on your PC with the global CUDA installation.
The first option is certainly easy to implement. But what if you want to run parts of your programs with Pytorch and parts with TF2? Options 2 and 3 require significant efforts ahead of any further updates of either TF and PyTorch. They also have the disadvantage that you cannot test the latest CUDA version for compatibility and performance of your ML-programs.
Function tensorflow.load_library to the rescue
Option 4 is based on providing a path to a certain so-library for cudnn on your Linux system. It will work in this form on your own Linux system, only, and is not suited for a productive version of your ML-application on another platform without proper modifications. But it is simple to use – and it can easily be eliminated as soon as your ML-programs are ripe for production.
Option 4 works because once you have loaded a certain library to be used by TF2, it will not be loaded again. Therefore, you can direct TF to our global so-library via providing a path to tensorflow.load_library (), before TF2 actually takes control of your computation device.
In my case the global installation of CUDA (via a respective repository for Opensuse) changed links in /usr/lib64 already properly to point to the directory of the system’s global CUDA-installation (you find it typically under /usr/local/cuda-xx.x or under /opt/cuda-xx.x on a Linux system). /If your links in /usr/lib64 are not set or do not fit the actual CUDA installation, you may need to change them manually.) I provide the following path very early in my Python programs in a section for loading modules:
import tensorflow as tf
tf.load_library("/usr/lib64/libcudnn.so") This worked perfectly, as the path leads to a link pointing to my 9.7.1 version of cudnn.so. I got no error messages and I could use Pytorch and TF2 in one and the same code (of course for two separately set up neural network models according to each platforms rules).
Conclusion
The coexistence of a local CUDA/cudnn installation in a Python environment can conflict with a global CUDA/cudnn installation on your Linux-system. Directing TF2 to load the right version of the cudnn-library so-module via a parameter to tf.load_library is an easy and controllable way to circumvent version problems. I hope that someone of the TF2 developers in the future invests some time in a better analysis of which cudnn so-module to load on a Linux system with a global CUDA installation – e.g. by following a respective path included in an environment variable LD_LIBRARY_PATH.