In Machine Learning we typically deal with huge, but finite vector distributions defined in the ℝn. At least in certain regions of the ℝn these distributions may approximate an underlying continuous distribution. In the first post of this series
we worked with a special type of continuous vector distribution based on independent 1-dimensional standardized normal distributions for the vector components. In this post we apply a linear transformation to the vectors of such a distribution. We restrict our present view onto transformations which can be represented by invertible quadratic (n x n) matrices M with constant real valued elements.
We will find that the resulting probability density function for the transformed vectors y = M • z are controlled by a symmetric invertible matrix Σ. These probability functions all have the same functional form based on a central product yT • Σ-1 • y. This result encourages a common definition of the corresponding vector distributions. We will call the resulting distributions “non-degenerate multivariate normal distribution“. They form a sub-set of more general multivariate normal distributions ([MNDs] or [MVNs]).
In this post I will closely follow a line of thought which many authors have published before. A prominent example is Prof. Richard Lockhart at the SFU, CA. See the following links to his lecture notes:
- https://www.sfu.ca/ ~lockhart/richard/ 802/02_3/ lectures/mvn/web.pdf
- https://www.sfu.ca/ ~lockhart/richard/ 830/13_3/ lectures/mvn/web.pdf
Any errors and incomplete derivations are my fault. Below I will use the abbreviation “pdf” for “probability density function”. Forthcoming posts we will deal with more general (n x m)-matrices and also singular, non-invertible (n x n) matrices.
Probability densities of random vectors with independent components
In the last post we introduced random vectors to represent certain statistical vector distributions. A random vector maps an object population to a distribution of vectors in the ℝn by a statistical process. So far we have regarded random vectors having independent normal random variables (maps to ℝ) as components. I.e. the distribution of the values of a chosen component of the (densely populated) vector distribution could be described by a continuous 1-dimensional Gaussian probability density function. We have distinguished a normalized random vector W from a standardized one, which we named Z, and used the following notation to indicate that the related distributions represented special cases of MVNs:
Remember that the probability density functions gw(w) and gz(z) for W– and Z-related distributions of vectors w and z
could be written as
It is easy to see that the contour-hypersurfaces of the probability density of the Z-distribution is given by surfaces of n-dimensional spheres.
Application of a linear, invertible transformation onto a random vector
In this post we look at a random vector Y which results in target vectors y ∈ ℝn that are related to target vectors z ∈ ℝn of our standardized random vector Z by a linear transformation:
The interpretation is that any vector z belonging to the Z-based distribution is transformed by My, i.e.: Any vector z of the distribution generated by Z would be transformed into y = My • z + μy. The following plot shows the result of such a transformation for a particular matrix:
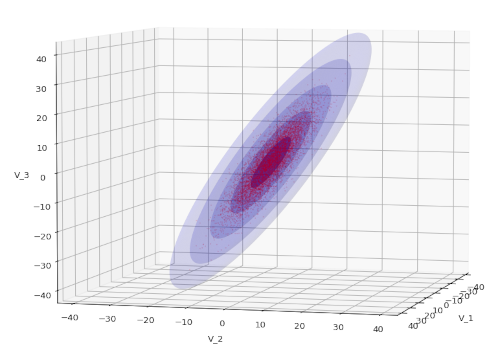
We assume that the matrix M is invertible. I.e. for the (n x n) matrix My exists a matrix My-1, such that
(Other cases will be handled in one of the forthcoming posts.) We then can write
We note the following relations (in a somewhat relaxed notation, both with respect to the bullets marking matrix multiplications and the random vectors):
The last relation is basic Linear Algebra [LinAlg]. See e.g. here.
Transformation of the probability density
How does our probability density function gz(z) transform? Remember that it is not sufficient to just rewrite the coordinate values in the density function. Instead we have to ensure that the product of the local density times an infinitesimal volume dV must remain constant during the coordinate transformation. Therefore we need the Jacobi-determinant of the variable transformation as an additional factor. (This is a basic theorem of multidimensional analysis for injective variable changes in multiple integrals and the transformation of infinitesimal volume elements).
For a linear transformation (like a rotation) the required determinant is just det(My) = |My|. Therefore:
Thus
Rewriting the probability density of the transformed distribution with the help of a symmetric and invertible matrix Σ
Let us try to bring probability density function [pdf] into a form similar to gw(w). We can now introduce a new matrix ΣY = My • MyT, for which we demand that it is invertible and that it has the following properties (from linear algebra for invertible matrices):
An invertible M guarantees us an invertible ΣY . Note that ΣY is symmetric by construction:
Thus also ΣY-1 is symmetric. It also follows that
With the help of ΣY and ΣY-1 we can rewrite our transformed pdf as
This result shows that the probability density functions of all transformed Y based on different linear and invertible transformations of Z have a common form. This gives rise to a general definition.
MND as the result of a linear automorphism
We now define:
A random vector Y ∈ Rn has a non-degenerate multivariate normal distribution if it has the same distribution as MZ + μ for some μ ∈ Rn and some invertible non-singular (n x n)- matrix M of constants and Z ∼ \( \pmb{\mathcal{N}}_n \left( \pmb{0}, \, \pmb{\operatorname{I}} \right) \)
A MND in the ℝn thus can be regarded as the result of an automorphism of vectors being members of our much simpler Z-based distribution. MNDs in general are the result of a particular sub-class of affine transformations, namely linear ones, applied to statistical distributions of vectors whose components follow independent, uncorrelated probability densities.
We will see in one of the next posts what this means in terms of geometrical figures.
The probability density of a non-degenerate multivariate normal distribution can be written as
for a symmetric, invertible and positive-definite Matrix Σ = MMT . For the positive definiteness see the next post. Due to the similarities with gw(w) we are tempted to interpret Σ as a “variance-covariance matrix”. But we actually have to prove this in one of the next posts.
Conclusion
In this post we have shown that a linear operation mediated by an invertible (n x n)-matrix M applied on a random vector Z with independent standardized normal components (in the sense of generating independent continuous and standardized 1-dim Gaussian distributions) gives rise to vector distributions whose probability density functions have a general common form controlled by an invertible symmetric matrix Σ = MMT and its inverse Σ-1. We called these vector distributions non-degenerate MNDs.
In the next post of this series
we will look a bit closer on the properties of Σ. We will find that, under our special assumptions about M, Σ is positive definite and therefore gives rise to a distance measure. We will see that a constant distance of vectors of a non-degenerate MND to its mean vector implies ellipsoidal contour-surfaces. In yet another post we will also show that a given positive-definite and symmetric Σ is not only invertible, but can always be decomposed into a product AAT of very specific and helpful matrices A=ΛQ (spectral decomposition) with the help of Σ‘s eigenvalues and eigenvectors.