In a previous post of this blog we have derived a function g2(x,y for the probability density of a Bivariate Normal Distribution [BVD] of two 1-dimensional random variables X and Y).
By rewriting the probability density function [pdf] in terms of vectors (x, y)T and a coupling matrix Σ-1 we recognized that a coefficient appearing in a central exponential of the pdf could be identified as the so called correlation coefficient ρ describing a linear coupling of our two random variables X and Y.
In this post I shall show how one can derive the covariance and the correlation coefficient the hard way by directly integrating the BVD’s probability density function.
Related posts:
- Probability density function of a Bivariate Normal Distribution – derived from assumptions on marginal distributions and functional factorization
- Bivariate normal distribution – derivation by linear transformation of a random vector for two independent Gaussians
A bit of motivation first
Just to motivate those of my readers a bit who may ask themselves what bivariate distributions have to do with Machine Learning. The following feature image shows data points forming a bivariate normal distribution whose pdf can be described by the type of function discussed in the preceding post and below.
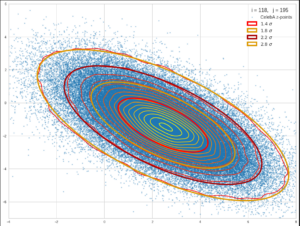
The data points correspond to vectors in the multidimensional latent space of a Convolutional AutoEncoder [CAE]. Each vector represents an image of a face after having been encoded by the encoder part of the trained CAE. The vector’s endpoints were projected onto a 2-dim coordinate plane of the basic Cartesian Coordinate System [CCS] spanning the latent space. We see that the contours of the resulting (projected) two 2-dimensional probability density are concentric ellipses whose main axes all point in the same directions. The axes of the ellipses obviously are rotated against the CCS axes. In future posts of this blog we will proof that the rotation angle of such ellipses directly depend on the correlation coefficient between underlying 1-dimensional distributions. The math of bivariate and multivariate distributions is also of further importance in ML-applications applied to data of industrial processes.
Formal definition of the covariance of two random variables X and Y
Let us abbreviate the expectation values of the random variables X and Y as E[X] and E[Y], respectively. Then the formal definition of the covariance of X and Y is:
XY is a combined two-dimensional distribution, which is defined by a probability density function g(x,y) resulting from a probability gx(x) of X assuming x and a conditional probability cy(y|x) of Y assuming y under the condition of X = x :
The second part giving rise to symmetry arguments. Then in general we have
The correlation coefficient ρ for the two random distributions is defined by looking at the standardized distributions Xn and Yn:
which after some elementary consideration gives us
To simplify the following steps we choose a 2-dimensional Cartesian coordinate system [CCS] centered such that E[X] = 0 and E[Y] = 0.
In the case of a centered “Bivariate Normal Distribution” [BVD] we call the respective probability function g2c(x,y) (see a previous post) . A centered BVD can always be achieved by moving the origin of the CCS appropriately. Using this pdf we find that we have to solve the following integral:
Useful integral formulas
We need formulas for two integrals :
Performing the integration
Assumptions on the marginal distributions X and Y (having variances σx2 and σy2) of a BVD and the application of symmetry arguments plus normalization conditions have revealed the general form of g2(x,y). See the preceding post in this blog. In our centered CCS the pdf of the (centered) BVD is given by
ρ is a parameter and constant in this formula. We know already that it might have to to with the correlation of the random variables X and Y. To prove this analytically we now perform the required integration to get an analytical expression for the covariance.
The trick to solve the integral over y is to complete the expression in the exponential such that we get a full square. First we redefine some variables
The term in the exponential can now be rewritten as
This gives us
We solve the inner integral with the help of (6) to get:
By application of (7) we arrive at
This is the result we have hoped for.
We obviously can identify the parameter ρ appearing in the probability density function of a bivariate normal distribution as the correlation coefficient between two underlying 1-dimensional marginal normal distributions.
In the preceding post we have seen that ρ appears in the matrix Σ-1 defining the quadratic form in the exponential. With v = (x, y)T we have
The central parameter ρ is also called the Pearson correlation coefficient.
For standardized Gaussian distributions X and Y (with σx = σy = 1) we get a very simple covariance matrix completely determined by ρ alone:
Conclusion
One can directly derive the correlation coefficient for the 1-dimensional Gaussian distributions underlying a Bivariate Normal Distribution [BVD] by deriving the expectation value for the product xy from the centered BVD’s probability density function g2c(x,y). The integrals over x and y have analytical solutions.
In reverse we can say that a BVD can be constructed via defining a correlation between two 1-dimensional normal distributions and using the inverse of the covariance matrix to define a quadratic form of x and y in an exponential, which after a normalization gives you the probability density function of the BVD.
We shall see in further posts that such a construction has a direct geometrical interpretation. This will later on also motivate the abstract definition of general multidimensional or Multivariate Normal Distributions and their probability density functions.
In further posts on BVDs I will derive the probability density in a more formal way, namely by a linear transformation of a random vector of two independent 1-dimensional normal Gaussian distributions. Stay tuned …